
Java中的集合类总共有三种:set、list(列表包含Queue)、map
- Collection: Collection是集合List、Set、Queue的基本接口
- Iterator:迭代器,可以通过迭代器来遍历集合数据,同时使用这种方法不会造成数据越界异常,所以在遍历删除的时候务必使用。
- Map:是映射表的基础接口。
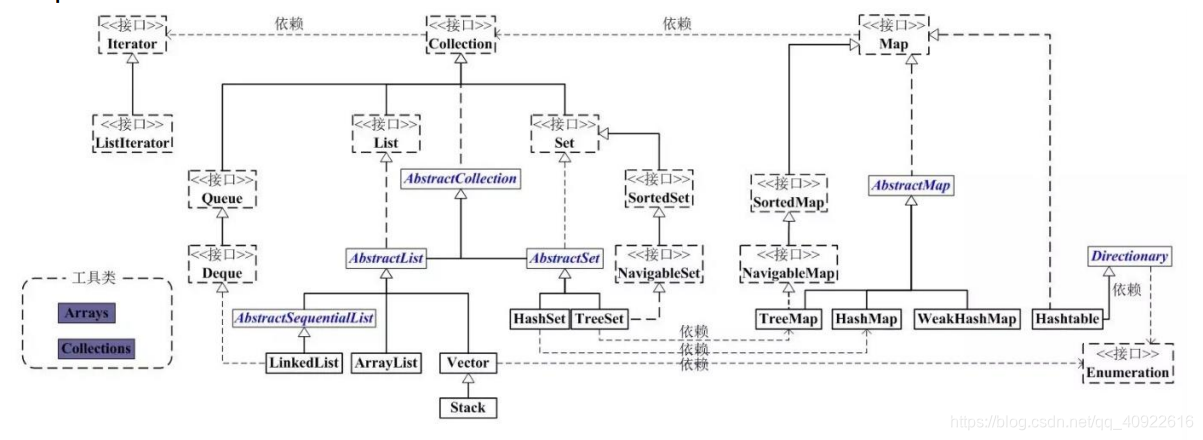
集合框架
List集合
| List集合 | 实现方式 | 排列顺序 | 增删改查 | 线程安全 | 特点 |
|---|---|---|---|---|---|
| ArrayList | 底层使用数组 | 排列有序,可重复 | 速度快、增删慢 | 线程不安全 | 容量不够时,扩容至当前*1.5+1 |
| Vector | 底层使用数组 | 排列有序,可重复 | 速度快、增删满 | 线程安全,加了synchronized | 容量不够,默认扩容一倍 |
| LinkedList | 底层使用双向循环链表数据结构 | 排列有序,可重复 | 查询慢、增删快 | 线程不安全 |
Set集合
| Set集合 | 实现方式 | 排列顺序 | 增删改查 | 线程安全 | 特点 |
|---|---|---|---|---|---|
| HashSet | 底层使用HashMap | 排列无序,不可重复、独一无二 | 存取速度快 | 线程不安全 | key可以为null,value为Object对象 |
| TreeSet | 底层使用二叉树 | 排列无序,不可重复 | 排序存储 | 线程不安全 | 内部是TreeMap的SortedSet |
| LinkedHashSet | 采用Hash表存储,并用双向链表记录插入顺序 | 排列有序,不可重复 | 存取速度快 | 线程不安全 | 内部是LinkedHashMap |
- HashSet:底层直接使用了HashMap,以存入的值为key,创建的一个static final Object对象为value

为什么HashSet的value不用null而是一个Object对象?
这就是需要从HashMap源码说起,HashMap的remove方法是去取key对应的node结点如果为null则返回null,如果有则返回node.value。 这就可能会有问题了,当我如果node.value的值存储为null,则无法判断是否删除成功。所以则需要存储一个非null的值。


- TreeSet:底层直接使用TreeMap,以存入的值为key,创建的一个static final Object对象为value,和HashSet极为类似 TreeMap底层用红黑树来存储数据结构,最直接的特点就是内部维系了个Comparator,比较和排序TreeMap中的元素。
Map集合
| Map集合 | 实现方式 | 排列顺序 | 增删改查 | 线程安全 | 特点 |
|---|---|---|---|---|---|
| HashMap | 底层使用Hash表 | 排列无序,key不可重复,值可以 | 存取速度快,每个链条在元素小于9的时候使用链表维护,大于等于9则转化为红黑树 | 线程不安全 | key可以null,value也可以为null |
| HashTable | 底层使用Hash表 | 排列无序,key不可重复,值可重复 | 存取速度快 | 线程安全 | key、value都不允许为null |
| TreeMap | 底层是红黑树 | 排列有序,key可重复定制Comparator方法 | 存取速度快 | 线程不安全 |
- HashMap:底层是一个内部类Node数组,每一项存放一个Node<k, v>结点,允许存key和value都为null。
- LinkedHashMap:是HashMap的一个子类,保证了记录的插入顺序,在用Iterator迭代的时候,先得到的肯定都先插入的。
- TreeMap:实现sortedMap接口,可按照规范排序的,默认是按键值的升序排序,也可以指定排序的比较器,当用 Iterator 遍历 TreeMap 时,得到的记录是排过序的。
HashMap的几个特性:
为什么HashMap数组长度为2^n:
- 为了提升计算效率,我们传统计算位置是使用 hashcode % length,但这种计算效率太低,所以改用位运算,在length = 2^n时候 hashcode%length = hashcode & (length-1)。
- 为了减少hash碰撞,当长度为2^n的时候,做&运算的时候,起关键作用的是hashcode。
构造方法中tableSizeFor()作用?为什么要加扰动函数hash():
- tableSizeFor的作用是为了输入任何值计算出大于且最接近他的一个为2^n数。
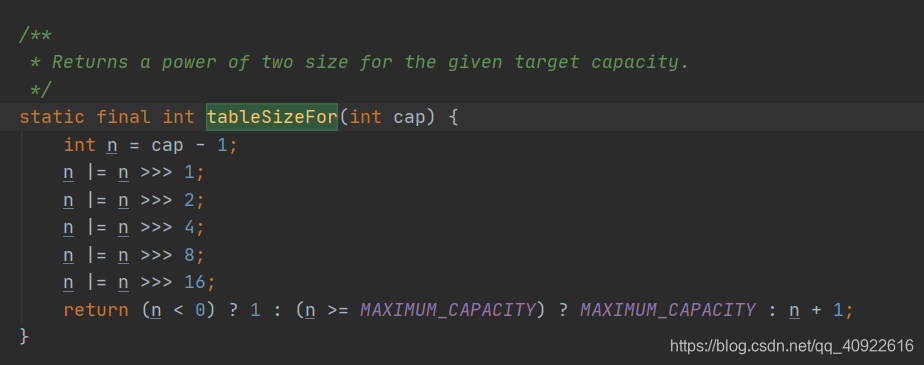
- 我们平时使用的HashMap容量都很小,基础为16,而hash值一般都是位数很长的一个数,所以当与运算的时候hash值高位的数是无法参与计算的,那么我们使用扰动函数的作用就是让hash的高16位也能参与运算中来。

为什么HashMap的数组需要扩容(resize())?
- 当我们hash表容量太小,插入的数据太多,那么就会就会导致链条上元素过多影响查找效率,那么就需要进行扩容,尽可能解决链化过长问题。


评论