
一、前言
我们经常可以在很多地方看到BlockingQueue的声影,最常见的就是在线程池中使用各式的阻塞队列。
在Java中,BlockingQueue是一个接口,它的实现类有ArrayBlockingQueue、DelayQueue、 LinkedBlockingQueue、PriorityBlockingQueue、SynchronousQueue等,它们的区别主要体现在存储 结构上或对元素操作上的不同,但是对于take与put操作的原理,却是类似的,目的都是阻塞存取。
二、阻塞与非阻塞
入队
add(E e):(非阻塞)调用offer但会根据offer结果,如果false抛出 IllegalStateException("Queue full") offer(E e):(非阻塞)如果队列没满,立即返回true; 如果队列满了,立即返回false put(E e):(阻塞)如果队列满了,一直阻塞,直到队列不满了或者线程被中断 offer(E e, long timeout, TimeUnit unit):在队尾插入一个元素,,如果队列已满,则进入等待,直到出现以下三种情况:
- 被唤醒
- 等待时间超时
- 当前线程被中断
出队
poll():(非阻塞)如果没有元素,直接返回null;如果有元素,出队 remove():(非阻塞)删除队列头元素,如果没有元素,返回false take():(阻塞)如果队列空了,一直阻塞,直到队列不为空或者线程被中断 poll(long timeout, TimeUnit unit):如果队列不空,出队;如果队列已空且已经超时,返回null;如果队列已空且时间未超时,则进入等待,直到出现以下三种情况:
- 被唤醒
- 等待时间超时
- 当前线程被中断
查看元素
element(): 调用peek(),查看元素,拿到为null,抛出 NoSuchElementException。 peek():查看元素,不去除,如果拿不到则为null。
三、常见队列特点
1. ArrayBlockingQueue
顾名思义数组阻塞队列,内部肯定以数组来做队列元素存储;
- 特点:ArrayBlockingQueue底层是使用一个数组实现队列的,内部使用了一把锁对插入和取出做了限制,即插或者取的操作是原子性
- 容量:需要指定一个大小,创建了无法修改
- 元素:不允许为null的元素插入
2.LinkedBlockingQueue
链表实现的阻塞队列,内部以Node结点类来存储元素,有固定大小
- 特点:内部有两把锁,插入和取出各一把,互不打扰,两个Condition来控制插入和取出数组阻塞唤醒。内部通过AtomicInteger count变量保证统计队列元素准确
- 容量:默认为Integer.MAX_VALUE
- 元素:不允许为null的元素插入
3.PriorityBlockingQueue
优先级阻塞队列,底层使用数组存储,依赖Comparator来实现优先级
- 特点:无界队列依赖Comparator来确保不同元素的排序位置,最大值不超过Integer.MAX_Value-8
- 容量:默认为11,底层使用数组来存储,会扩容
- 元素:不允许为null的元素插入
注:PriorityBlockingQueue并不会阻塞数据生产者,而只会在没有可消费的数据时,阻塞数据的消费者。
4.DelayQueue
延迟队列,底层存放实现了Delayed接口的对象
- 特点:存储Delayed元素,可实现延时等功能
- 容量:默认为11,底层使用PriorityBlockingQueue来存储
- 元素:不允许为null的元素插入,内部存储Delay的实现类元素
- take:内部使用priorityblockingqueue排序,根据getDelay判断剩余时间, 只有当前到点了,才可以取出元素
Delayed接口:
public interface Delayed extends Comparable<Delayed> {
long getDelay(TimeUnit var1);
}
getDelay() 获取剩余时间 compareTo() 比较结果 内部队列的实现依照这两个方法
Thread的Leader线程作用:
DelayQueue实现Leader-Follower pattern
1、当存在多个take线程时,同时只生效一个,即,leader线程
2、当leader存在时,其它的take线程均为follower,其等待是通过condition实现的
3、当leader不存在时,当前线程即成为leader,在delay之后,将leader角色释放还原
4、最后如果队列还有内容,且leader空缺,则调用一次condition的signal,唤醒挂起的take线程,其中之一将成为新的leader
5、最后在finally中释放锁
5.SynchronousQueue
一种无缓冲的等待队列,相对于有缓冲的BlockingQueue来说,少了一个中间经销商的环节(缓冲区)。消费者必须亲自去集市找到所要商品的直接生产者。
- 特点:一对一,生产者和消费者缺一就阻塞,存在公平和非公平两种
- 容量:size默认为0,剩余容量也为0
- 元素:不允许为null的元素插入
实现原理
来源:https://blog.csdn.net/yanyan19880509/article/details/52562039
公平模式
底层实现使用的是TransferQueue这个内部队列,它有一个head和tail指针,用于指向当前正在等待匹配的线程节点。
初始化时,TransferQueue的状态如下:
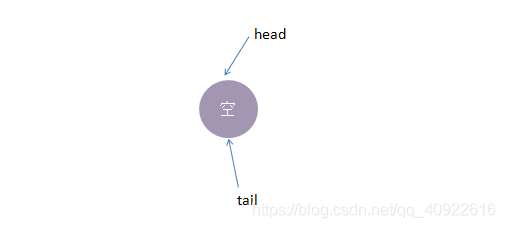 接着我们进行一些操作:
接着我们进行一些操作:
1、线程put1执行 put(1)操作,由于当前没有配对的消费线程,所以put1线程入队列,自旋一小会后睡眠等待,这时队列状态如下
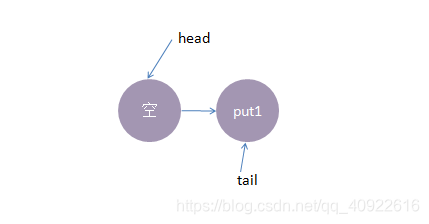
2、接着,线程put2执行了put(2)操作,跟前面一样,put2线程入队列,自旋一小会后睡眠等待,这时队列状态如下:
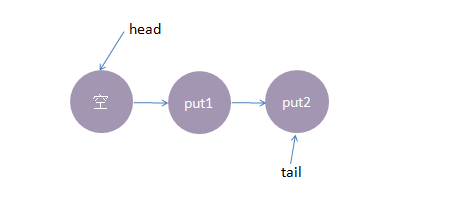
3、这时候,来了一个线程take1,执行了 take操作,由于tail指向put2线程,put2线程跟take1线程配对了(一put一take),这时take1线程不需要入队,但是请注意了,这时候,要唤醒的线程并不是put2,而是put1。为何? 大家应该知道我们现在讲的是公平策略,所谓公平就是谁先入队了,谁就优先被唤醒,我们的例子明显是put1应该优先被唤醒。至于读者可能会有一个疑问,明明是take1线程跟put2线程匹配上了,结果是put1线程被唤醒消费,怎么确保take1线程一定可以和次首节点(head.next)也是匹配的呢?其实大家可以拿个纸画一画,就会发现真的就是这样的。 公平策略总结下来就是:队尾匹配队头出队。 执行后put1线程被唤醒,take1线程的 take()方法返回了1(put1线程的数据),这样就实现了线程间的一对一通信,这时候内部状态如下:
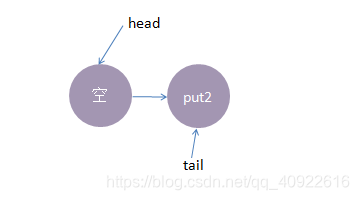
4、最后,再来一个线程take2,执行take操作,这时候只有put2线程在等候,而且两个线程匹配上了,线程put2被唤醒, take2线程take操作返回了2(线程put2的数据),这时候队列又回到了起点,如下所示:
以上便是公平模式下,SynchronousQueue的实现模型。总结下来就是:队尾匹配队头出队,先进先出,体现公平原则。
非公平模式 我们还是使用跟公平模式下一样的操作流程,对比两种策略下有何不同。非公平模式底层的实现使用的是TransferStack, 一个栈,实现中用head指针指向栈顶,接着我们看看它的实现模型:
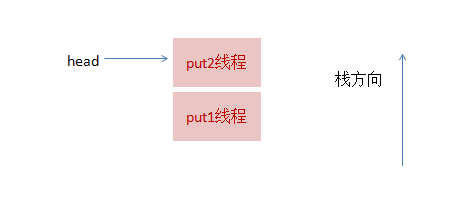
1、线程put1执行 put(1)操作,由于当前没有配对的消费线程,所以put1线程入栈,自旋一小会后睡眠等待,这时栈状态如下

2、接着,线程put2再次执行了put(2)操作,跟前面一样,put2线程入栈,自旋一小会后睡眠等待,这时栈状态如下:
3、这时候,来了一个线程take1,执行了take操作,这时候发现栈顶为put2线程,匹配成功,但是实现会先把take1线程入栈,然后take1线程循环执行匹配put2线程逻辑,一旦发现没有并发冲突,就会把栈顶指针直接指向 put1线程

4、最后,再来一个线程take2,执行take操作,这跟步骤3的逻辑基本是一致的,take2线程入栈,然后在循环中匹配put1线程,最终全部匹配完毕,栈变为空,恢复初始状态,如下图所示:

可以从上面流程看出,虽然put1线程先入栈了,但是却是后匹配,这就是非公平的由来。
20210506更新
6.TransferQueue
LinkedTransferQueue是在JDK1.7时,J.U.C包新增的一种比较特殊的阻塞队列,它除了具备阻塞队列的常用功能外,还有一个比较特殊的transfer方法。
我们知道,在普通阻塞队列中,当队列为空时,消费者线程(调用take或poll方法的线程)一般会阻塞等待生产者线程往队列中存入元素。而LinkedTransferQueue的transfer方法则比较特殊:
- 当有消费者线程阻塞等待时,调用transfer方法的生产者线程不会将元素存入队列,而是直接将元素传递给消费者;
- 如果调用transfer方法的生产者线程发现没有正在等待的消费者线程,则会将元素入队,然后会阻塞等待,直到有一个消费者线程来获取该元素。
LinkedTransferQueue其实兼具了SynchronousQueue的特性以及无锁算法的性能,并且是一种无界队列: 另外,由于LinkedTransferQueue可以存放两种不同类型的结点,所以称之为“Dual Queue”: 内部Node结点定义了一个 boolean 型字段——isData,表示该结点是“数据结点”还是“请求结点”。
为了节省 CAS 操作的开销,LinkedTransferQueue使用了松弛(slack)操作: 在结点被匹配(被删除)之后,不会立即更新队列的head、tail,而是当 head、tail结点与最近一个未匹配的结点之间的距离超过“松弛阀值”后才会更新(默认为 2)。这个“松弛阀值”一般为1到3,如果太大会增加沿链表查找未匹配结点的时间,太小会增加 CAS 的开销。
可以看出SynchronousQueue和LinkedTransferQueue很像,都是生产者消费者出现才会解除阻塞。那有什么区别呢,这边根据自己学习总结了一下。
- SynchronousQueue没有容量的,即没有缓存队列,当生产者生产时候线程会按照先后顺序排序,当消费者进入时候,根据公平/非公平选择对应生成线程唤醒,交换元素。
- LinkedTransferQueue内部多了transfer、trytransfer等方法,检测是否有线程在等待,而如果没有就放入队列后阻塞,如果检测到就立即发送新增的数据给这个线程获取而不用放入队列。所以当使用tryTransfer和transfer往LinkedTransferQueue添加多个数据的时候,添加一个数据后,会先唤醒等待的获取数据的线程,再继续添加数据。
总结:
五种常见的阻塞队列,各有各的特点,我们需要结合具体情景选择适用的阻塞队列
- ArrayBlockingQueue:需要创建队列数组长度。
- LinkedBlockingQueue:内部使用Node实现,默认大小Integer.MAX_VALUE。
- PriorityBlockingQueue:优先级队列,默认大小11,内部需实现Comparator来比较。
- DelayQueue:延时队列,元素需要实现Delayed,底层使用PriorityBlockingQueue,默认大小11。
- SynchronousQueue:交换队列,默认大小0,需同时存在生产者和消费者,否则任一都会阻塞
- LinkedTransferQueue:新增transfer方法,tryTransfer和transfer可以检测是否有线程在等待获取数据,如果检测到就立即发送新增的数据给这个线程获取而不用放入队列。
| 队列特性 | 有界队列 | 近似无界队列 | 无界队列 | 特殊队列 |
|---|---|---|---|---|
| 有锁算法 | ArrayBlockingQueue | LinkedBlockingQueue、LinkedBlockingDeque | / | PriorityBlockingQueue、DelayQueue |
| 无锁算法 | / | / | LinkedTransferQueue | SynchronousQueue |
参考:https://www.cnblogs.com/snow826520/p/7699545.html
https://blog.csdn.net/yanyan19880509/article/details/52562039
https://segmentfault.com/a/1190000016460411?utm_source=sf-similar-article


评论